When we show that the results of our study are "statistically significant" we feel that the study was worth the effort, that we have met our objectives. This is because the current meaning of the word "significant" implies that something is important or consequential but, unfortunately, that was not its intended meaning. (See John Cook's blog "The Endeavor" for a nice post on the Origin of “statistically significant”).
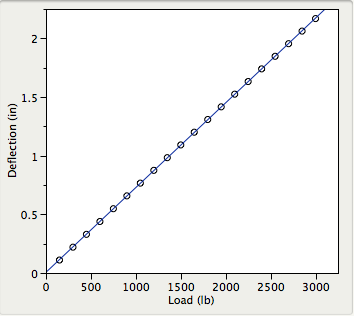
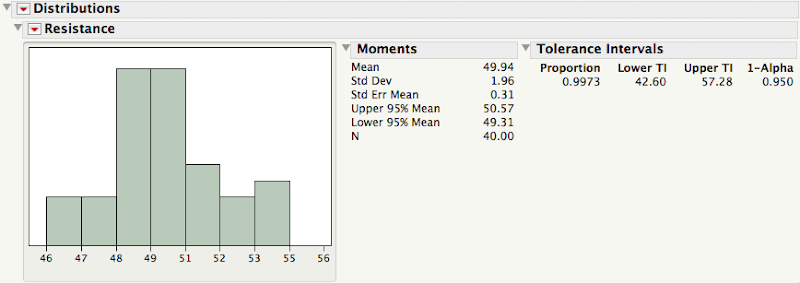
Let's say we need to to make a claim about the average DC resistance of a certain type of cable we manufacture. We set up the null hypothesis as μ=50 Ohm vs. the alternative hypothesis μ≠50 Ohm, and measure the resistance of 40 such cables. If the one-sample t-test, based on the sample of 40 cables, is statistically significant we can claim that the average DC resistance is different from 50 Ohm. Our claim does not imply that this difference is of any practical importance, this depends on the size of the difference, just that the average DC resistance is not 50 Ohm. A test of significance is a test of difference. This is the operational definition given to the term "statistical significance" by Sir Ronald Fisher in his 1925 book Statistical Methods for Research Workers: “Critical tests of this kind may be called tests of significance, and when such tests are available we may discover whether a second sample is or is not significantly different from the first" (emphasis mine).
What if we do not reject the null hypothesis μ=50 Ohm? Although tests of significance are set up to demonstrate difference not equality, we sometimes take this lack of evidence as evidence that the average DC resistance is in fact 50 Ohm. This is because in practice we encounter situations where we need to demonstrate to a customer, or government agency, that the average DC resistance is "close" to 50 Ohm. In the context of significance testing what we need to do is to swap the null and alternative hypothesis and test for equivalence within a given bound; i.e., test μ≠50 Ohm vs. |μ-50 Ohm|< δ, where δ is a small number. In the next post Brenda discusses how a test of equivalence is a great way of combining statistical with practical significance.